



















SpringBoot数据交互

深入SpringBoot数据交互
前面我们了解了SpringBoot以及一些常用的框架整合,相信各位小伙伴已经体验到SpringBoot带来的超便捷开发体验了。本章我们将深入讲解SpringBoot的数据交互,使用更多方便好用的持久层框架。
JDBC交互框架
除了我们前面一直认识的Mybatis之外,实际上Spring官方也提供了一个非常方便的JDBC操作工具,它同样可以快速进行增删改查。首先我们还是通过starter将依赖导入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
导入完成之后就可以轻松使用了。
JDBC模版类
Spring JDBC为我们提供了一个非常方便的JdbcTemplate类,它封装了常用的JDBC操作,我们可以快速使用这些方法来实现增删改查,这里我们还是配置一下MySQL数据源信息:
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
spring:
datasource:
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
我们要操作数据库,最简单直接的方法就是使用JdbcTemplate来完成:
@Resource
JdbcTemplate template;
它给我们封装了很多方法使用,比如我们要查询数据库中的一条记录:

我们可以使用queryForMap快速以Map为结果的形式查询一行数据:
@Test
void contextLoads() {
Map<String, Object> map = template.queryForMap("select * from user where id = ?", 1);
System.out.println(map);
}
非常方便:

我们也可以编写自定义的Mapper用于直接得到查询结果:
@Data
@AllArgsConstructor
public class User {
int id;
String name;
String email;
String password;
}
@Test
void contextLoads() {
User user = template.queryForObject("select * from user where id = ?",
(r, i) -> new User(r.getInt(1), r.getString(2), r.getString(3), r.getString(4)), 1);
System.out.println(user);
}
当然除了这些之外,它还提供了update方法适用于各种情况的查询、更新、删除操作:
@Test
void contextLoads() {
int update = template.update("insert into user values(2, 'admin', '654321@qq.com', '123456')");
System.out.println("更新了 "+update+" 行");
}
这样,如果是那种非常小型的项目,甚至是测试用例的话,都可以快速使用JdbcTemplate快速进行各种操作。
JDBC简单封装
对于一些插入操作,Spring JDBC为我们提供了更方便的SimpleJdbcInsert工具,它可以实现更多高级的插入功能,比如我们的表主键采用的是自增ID,那么它支持插入后返回自动生成的ID,这就非常方便了:
@Configuration
public class WebConfiguration {
@Resource
DataSource source;
@Test
void contextLoads() {
//这个类需要自己创建对象
SimpleJdbcInsert simple = new SimpleJdbcInsert(source)
.withTableName("user") //设置要操作的表名称
.usingGeneratedKeyColumns("id"); //设置自增主键列
Map<String, Object> user = new HashMap<>(2); //插入操作需要传入一个Map作为数据
user.put("name", "bob");
user.put("email", "112233@qq.com");
user.put("password", "123456");
Number number = simple.executeAndReturnKey(user); //最后得到的Numver就是得到的自增主键
System.out.println(number);
}
}
这样就可以快速进行插入操作并且返回自增主键了,还是挺方便的。

当然,虽然SpringJDBC给我们提供了这些小工具,但是其实只适用于简单小项目,稍微复杂一点就不太适合了,下一部分我们将介绍JPA框架。
JPA框架

- 用了Mybatis之后,你看那个JDBC,真是太逊了。
- 这么说,你的项目很勇哦?
- 开玩笑,我的写代码超勇的好不好。
- 阿伟,你可曾幻想过有一天你的项目里不再有SQL语句?
- 不再有SQL语句?那我怎么和数据库交互啊?
- 我看你是完全不懂哦
- 懂,懂什么啊?
- 你想懂?来,到我项目里来,我给你看点好康的。
- 好康?是什么新框架哦?
- 什么新框架,比新框架还刺激,还可以让你的项目登duang郎哦。
- 哇,杰哥,你项目里面都没SQL语句诶,这是用的什么框架啊?
在我们之前编写的项目中,我们不难发现,实际上大部分的数据库交互操作,到最后都只会做一个事情,那就是把数据库中的数据映射为Java中的对象。比如我们要通过用户名去查找对应的用户,或是通过ID查找对应的学生信息,在使用Mybatis时,我们只需要编写正确的SQL语句就可以直接将获取的数据映射为对应的Java对象,通过调用Mapper中的方法就能直接获得实体类,这样就方便我们在Java中数据库表中的相关信息了。
但是以上这些操作都有一个共性,那就是它们都是通过某种条件去进行查询,而最后的查询结果,都是一个实体类,所以你会发现你写的很多SQL语句都是一个套路select * from xxx where xxx=xxx,实际上对于这种简单SQL语句,我们完全可以弄成一个模版来使用,那么能否有一种框架,帮我们把这些相同的套路给封装起来,直接把这类相似的SQL语句给屏蔽掉,不再由我们编写,而是让框架自己去组合拼接。
认识SpringData JPA
首先我们来看一个国外的统计:

不对吧,为什么Mybatis这么好用,这么强大,却只有10%的人喜欢呢?然而事实就是,在国外JPA几乎占据了主导地位,而Mybatis并不像国内那样受待见,所以你会发现,JPA都有SpringBoot的官方直接提供的starter,而Mybatis没有,直到SpringBoot 3才开始加入到官方模版中。
那么,什么是JPA?
JPA(Java Persistence API)和JDBC类似,也是官方定义的一组接口,但是它相比传统的JDBC,它是为了实现ORM而生的,即Object-Relationl Mapping,它的作用是在关系型数据库和对象之间形成一个映射,这样,我们在具体的操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了。
其中比较常见的JPA实现有:
- Hibernate:Hibernate是JPA规范的一个具体实现,也是目前使用最广泛的JPA实现框架之一。它提供了强大的对象关系映射功能,可以将Java对象映射到数据库表中,并提供了丰富的查询语言和缓存机制。
- EclipseLink:EclipseLink是另一个流行的JPA实现框架,由Eclipse基金会开发和维护。它提供了丰富的特性,如对象关系映射、缓存、查询语言和连接池管理等,并具有较高的性能和可扩展性。
- OpenJPA:OpenJPA是Apache基金会的一个开源项目,也是JPA规范的一个实现。它提供了高性能的JPA实现和丰富的特性,如延迟加载、缓存和分布式事务等。
- TopLink:TopLink是Oracle公司开发的一个对象关系映射框架,也是JPA规范的一个实现。虽然EclipseLink已经取代了TopLink成为Oracle推荐的JPA实现,但TopLink仍然得到广泛使用。
在之前,我们使用JDBC或是Mybatis来操作数据,通过直接编写对应的SQL语句来实现数据访问,但是我们发现实际上我们在Java中大部分操作数据库的情况都是读取数据并封装为一个实体类,因此,为什么不直接将实体类直接对应到一个数据库表呢?也就是说,一张表里面有什么属性,那么我们的对象就有什么属性,所有属性跟数据库里面的字段一一对应,而读取数据时,只需要读取一行的数据并封装为我们定义好的实体类既可以,而具体的SQL语句执行,完全可以交给框架根据我们定义的映射关系去生成,不再由我们去编写,因为这些SQL实际上都是千篇一律的。
而实现JPA规范的框架一般最常用的就是Hibernate,它是一个重量级框架,学习难度相比Mybatis也更高一些,而SpringDataJPA也是采用Hibernate框架作为底层实现,并对其加以封装。
官网:https://spring.io/projects/spring-data-jpa
使用JPA快速上手
同样的,我们只需要导入stater依赖即可:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
接着我们可以直接创建一个类,比如用户类,我们只需要把一个账号对应的属性全部定义好即可:
@Data
public class Account {
int id;
String username;
String password;
}
接着,我们可以通过注解形式,在属性上添加数据库映射关系,这样就能够让JPA知道我们的实体类对应的数据库表长啥样,这里用到了很多注解:
@Data
@Entity //表示这个类是一个实体类
@Table(name = "account") //对应的数据库中表名称
public class Account {
@GeneratedValue(strategy = GenerationType.IDENTITY) //生成策略,这里配置为自增
@Column(name = "id") //对应表中id这一列
@Id //此属性为主键
int id;
@Column(name = "username") //对应表中username这一列
String username;
@Column(name = "password") //对应表中password这一列
String password;
}
接着我们来修改一下配置文件,把日志打印给打开:
spring:
jpa:
#开启SQL语句执行日志信息
show-sql: true
hibernate:
#配置为检查数据库表结构,没有时会自动创建
ddl-auto: update
ddl-auto属性用于设置自动表定义,可以实现自动在数据库中为我们创建一个表,表的结构会根据我们定义的实体类决定,它有以下几种:
none: 不执行任何操作,数据库表结构需要手动创建。create: 框架在每次运行时都会删除所有表,并重新创建。create-drop: 框架在每次运行时都会删除所有表,然后再创建,但在程序结束时会再次删除所有表。update: 框架会检查数据库表结构,如果与实体类定义不匹配,则会做相应的修改,以保持它们的一致性。validate: 框架会检查数据库表结构与实体类定义是否匹配,如果不匹配,则会抛出异常。
这个配置项的作用是为了避免手动管理数据库表结构,使开发者可以更方便地进行开发和测试,但在生产环境中,更推荐使用数据库迁移工具来管理表结构的变更。
我们可以在日志中发现,在启动时执行了如下SQL语句:

我们的数据库中对应的表已经自动创建好了。
我们接着来看如何访问我们的表,我们需要创建一个Repository实现类:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
}
注意JpaRepository有两个泛型,前者是具体操作的对象实体,也就是对应的表,后者是ID的类型,接口中已经定义了比较常用的数据库操作。编写接口继承即可,我们可以直接注入此接口获得实现类:
@Resource
AccountRepository repository;
@Test
void contextLoads() {
Account account = new Account();
account.setUsername("小红");
account.setPassword("1234567");
System.out.println(repository.save(account).getId()); //使用save来快速插入数据,并且会返回插入的对象,如果存在自增ID,对象的自增id属性会自动被赋值,这就很方便了
}
执行结果如下:

同时,查询操作也很方便:
@Test
void contextLoads() {
//默认通过通过ID查找的方法,并且返回的结果是Optional包装的对象,非常人性化
repository.findById(1).ifPresent(System.out::println);
}
得到结果为:

包括常见的一些计数、删除操作等都包含在里面,仅仅配置应该接口就能完美实现增删改查:

我们发现,使用了JPA之后,整个项目的代码中没有出现任何的SQL语句,可以说是非常方便了,JPA依靠我们提供的注解信息自动完成了所有信息的映射和关联。
相比Mybatis,JPA几乎就是一个全自动的ORM框架,而Mybatis则顶多算是半自动ORM框架。
方法名称拼接自定义SQL
虽然接口预置的方法使用起来非常方便,但是如果我们需要进行条件查询等操作或是一些判断,就需要自定义一些方法来实现,同样的,我们不需要编写SQL语句,而是通过方法名称的拼接来实现条件判断,这里列出了所有支持的条件判断名称:
| 属性 | 拼接方法名称示例 | 执行的语句 |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull,Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1(参数与附加%绑定) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1(参数与前缀%绑定) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1(参数绑定以%包装) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection | … where x.age not in ?1 |
| True | findByActiveTrue | … where x.active = true |
| False | findByActiveFalse | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
比如我们想要实现根据用户名模糊匹配查找用户:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
//按照表中的规则进行名称拼接,不用刻意去记,IDEA会有提示
List<Account> findAllByUsernameLike(String str);
}
我们来测试一下:
@Test
void contextLoads() {
repository.findAllByUsernameLike("%明%").forEach(System.out::println);
}

又比如我们想同时根据用户名和ID一起查询:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
List<Account> findAllByUsernameLike(String str);
Account findByIdAndUsername(int id, String username);
//也可以使用Optional类进行包装,Optional<Account> findByIdAndUsername(int id, String username);
}
@Test
void contextLoads() {
System.out.println(repository.findByIdAndUsername(1, "小明"));
}
比如我们想判断数据库中是否存在某个ID的用户:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
List<Account> findAllByUsernameLike(String str);
Account findByIdAndUsername(int id, String username);
//使用exists判断是否存在
boolean existsAccountById(int id);
}
注意自定义条件操作的方法名称一定要遵循规则,不然会出现异常:
Caused by: org.springframework.data.repository.query.QueryCreationException: Could not create query for public abstract ...
有了这些操作,我们在编写一些简单SQL的时候就很方便了,用久了甚至直接忘记SQL怎么写。
关联查询
在实际开发中,比较常见的场景还有关联查询,也就是我们会在表中添加一个外键字段,而此外键字段又指向了另一个表中的数据,当我们查询数据时,可能会需要将关联数据也一并获取,比如我们想要查询某个用户的详细信息,一般用户简略信息会单独存放一个表,而用户详细信息会单独存放在另一个表中。当然,除了用户详细信息之外,可能在某些电商平台还会有用户的购买记录、用户的购物车,交流社区中的用户帖子、用户评论等,这些都是需要根据用户信息进行关联查询的内容。

我们知道,在JPA中,每张表实际上就是一个实体类的映射,而表之间的关联关系,也可以看作对象之间的依赖关系,比如用户表中包含了用户详细信息的ID字段作为外键,那么实际上就是用户表实体中包括了用户详细信息实体对象:
@Data
@Entity
@Table(name = "users_detail")
public class AccountDetail {
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Id
int id;
@Column(name = "address")
String address;
@Column(name = "email")
String email;
@Column(name = "phone")
String phone;
@Column(name = "real_name")
String realName;
}
而用户信息和用户详细信息之间形成了一对一的关系,那么这时我们就可以直接在类中指定这种关系:
@Data
@Entity
@Table(name = "users")
public class Account {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
@Id
int id;
@Column(name = "username")
String username;
@Column(name = "password")
String password;
@JoinColumn(name = "detail_id") //指定存储外键的字段名称
@OneToOne //声明为一对一关系
AccountDetail detail;
}
在修改实体类信息后,我们发现在启动时也进行了更新,日志如下:
Hibernate: alter table users add column detail_id integer
Hibernate: create table users_detail (id integer not null auto_increment, address varchar(255), email varchar(255), phone varchar(255), real_name varchar(255), primary key (id)) engine=InnoDB
Hibernate: alter table users add constraint FK7gb021edkxf3mdv5bs75ni6jd foreign key (detail_id) references users_detail (id)
是不是感觉非常方便!都懒得去手动改表结构了。
接着我们往用户详细信息中添加一些数据,一会我们可以直接进行查询:
@Test
void pageAccount() {
repository.findById(1).ifPresent(System.out::println);
}
查询后,可以发现,得到如下结果:
Hibernate: select account0_.id as id1_0_0_, account0_.detail_id as detail_i4_0_0_, account0_.password as password2_0_0_, account0_.username as username3_0_0_, accountdet1_.id as id1_1_1_, accountdet1_.address as address2_1_1_, accountdet1_.email as email3_1_1_, accountdet1_.phone as phone4_1_1_, accountdet1_.real_name as real_nam5_1_1_ from users account0_ left outer join users_detail accountdet1_ on account0_.detail_id=accountdet1_.id where account0_.id=?
Account(id=1, username=Test, password=123456, detail=AccountDetail(id=1, address=四川省成都市青羊区, email=8371289@qq.com, phone=1234567890, realName=本伟))
也就是,在建立关系之后,我们查询Account对象时,会自动将关联数据的结果也一并进行查询。
那要是我们只想要Account的数据,不想要用户详细信息数据怎么办呢?我希望在我要用的时候再获取详细信息,这样可以节省一些网络开销,我们可以设置懒加载,这样只有在需要时才会向数据库获取:
@JoinColumn(name = "detail_id")
@OneToOne(fetch = FetchType.LAZY) //将获取类型改为LAZY
AccountDetail detail;
接着我们测试一下:
@Transactional //懒加载属性需要在事务环境下获取,因为repository方法调用完后Session会立即关闭
@Test
void pageAccount() {
repository.findById(1).ifPresent(account -> {
System.out.println(account.getUsername()); //获取用户名
System.out.println(account.getDetail()); //获取详细信息(懒加载)
});
}
接着我们来看看控制台输出了什么:
Hibernate: select account0_.id as id1_0_0_, account0_.detail_id as detail_i4_0_0_, account0_.password as password2_0_0_, account0_.username as username3_0_0_ from users account0_ where account0_.id=?
Test
Hibernate: select accountdet0_.id as id1_1_0_, accountdet0_.address as address2_1_0_, accountdet0_.email as email3_1_0_, accountdet0_.phone as phone4_1_0_, accountdet0_.real_name as real_nam5_1_0_ from users_detail accountdet0_ where accountdet0_.id=?
AccountDetail(id=1, address=四川省成都市青羊区, email=8371289@qq.com, phone=1234567890, realName=卢本)
可以看到,获取用户名之前,并没有去查询用户的详细信息,而是当我们获取详细信息时才进行查询并返回AccountDetail对象。
那么我们是否也可以在添加数据时,利用实体类之间的关联信息,一次性添加两张表的数据呢?可以,但是我们需要稍微修改一下级联关联操作设定:
@JoinColumn(name = "detail_id")
@OneToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL) //设置关联操作为ALL
AccountDetail detail;
- ALL:所有操作都进行关联操作
- PERSIST:插入操作时才进行关联操作
- REMOVE:删除操作时才进行关联操作
- MERGE:修改操作时才进行关联操作
可以多个并存,接着我们来进行一下测试:
@Test
void addAccount(){
Account account = new Account();
account.setUsername("Nike");
account.setPassword("123456");
AccountDetail detail = new AccountDetail();
detail.setAddress("重庆市渝中区解放碑");
detail.setPhone("1234567890");
detail.setEmail("73281937@qq.com");
detail.setRealName("张三");
account.setDetail(detail);
account = repository.save(account);
System.out.println("插入时,自动生成的主键ID为:"+account.getId()+",外键ID为:"+account.getDetail().getId());
}
可以看到日志结果:
Hibernate: insert into users_detail (address, email, phone, real_name) values (?, ?, ?, ?)
Hibernate: insert into users (detail_id, password, username) values (?, ?, ?)
插入时,自动生成的主键ID为:6,外键ID为:3
结束后会发现数据库中两张表都同时存在数据。
接着我们来看一对多关联,比如每个用户的成绩信息:
@JoinColumn(name = "uid") //注意这里的name指的是Score表中的uid字段对应的就是当前的主键,会将uid外键设置为当前的主键
@OneToMany(fetch = FetchType.LAZY, cascade = CascadeType.REMOVE) //在移除Account时,一并移除所有的成绩信息,依然使用懒加载
List<Score> scoreList;
@Data
@Entity
@Table(name = "users_score") //成绩表,注意只存成绩,不存学科信息,学科信息id做外键
public class Score {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
@Id
int id;
@OneToOne //一对一对应到学科上
@JoinColumn(name = "cid")
Subject subject;
@Column(name = "socre")
double score;
@Column(name = "uid")
int uid;
}
@Data
@Entity
@Table(name = "subjects") //学科信息表
public class Subject {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cid")
@Id
int cid;
@Column(name = "name")
String name;
@Column(name = "teacher")
String teacher;
@Column(name = "time")
int time;
}
在数据库中填写相应数据,接着我们就可以查询用户的成绩信息了:
@Transactional
@Test
void test() {
repository.findById(1).ifPresent(account -> {
account.getScoreList().forEach(System.out::println);
});
}
成功得到用户所有的成绩信息,包括得分和学科信息。
同样的,我们还可以将对应成绩中的教师信息单独分出一张表存储,并建立多对一的关系,因为多门课程可能由同一个老师教授(千万别搞晕了,一定要理清楚关联关系,同时也是考验你的基础扎不扎实):
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "tid") //存储教师ID的字段,和一对一是一样的,也会当前表中创个外键
Teacher teacher;
接着就是教师实体类了:
@Data
@Entity
@Table(name = "teachers")
public class Teacher {
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Id
int id;
@Column(name = "name")
String name;
@Column(name = "sex")
String sex;
}
最后我们再进行一下测试:
@Transactional
@Test
void test() {
repository.findById(3).ifPresent(account -> {
account.getScoreList().forEach(score -> {
System.out.println("课程名称:"+score.getSubject().getName());
System.out.println("得分:"+score.getScore());
System.out.println("任课教师:"+score.getSubject().getTeacher().getName());
});
});
}
成功得到多对一的教师信息。
最后我们再来看最复杂的情况,现在我们一门课程可以由多个老师教授,而一个老师也可以教授多个课程,那么这种情况就是很明显的多对多场景,现在又该如何定义呢?我们可以像之前一样,插入一张中间表表示教授关系,这个表中专门存储哪个老师教哪个科目:
@ManyToMany(fetch = FetchType.LAZY) //多对多场景
@JoinTable(name = "teach_relation", //多对多中间关联表
joinColumns = @JoinColumn(name = "cid"), //当前实体主键在关联表中的字段名称
inverseJoinColumns = @JoinColumn(name = "tid") //教师实体主键在关联表中的字段名称
)
List<Teacher> teacher;
接着,JPA会自动创建一张中间表,并自动设置外键,我们就可以将多对多关联信息编写在其中了。
JPQL自定义SQL语句
虽然SpringDataJPA能够简化大部分数据获取场景,但是难免会有一些特殊的场景,需要使用复杂查询才能够去完成,这时你又会发现,如果要实现,只能用回Mybatis了,因为我们需要自己手动编写SQL语句,过度依赖SpringDataJPA会使得SQL语句不可控。
使用JPA,我们也可以像Mybatis那样,直接编写SQL语句,不过它是JPQL语言,与原生SQL语句很类似,但是它是面向对象的,当然我们也可以编写原生SQL语句。
比如我们要更新用户表中指定ID用户的密码:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
@Transactional //DML操作需要事务环境,可以不在这里声明,但是调用时一定要处于事务环境下
@Modifying //表示这是一个DML操作
@Query("update Account set password = ?2 where id = ?1") //这里操作的是一个实体类对应的表,参数使用?代表,后面接第n个参数
int updatePasswordById(int id, String newPassword);
}
@Test
void updateAccount(){
repository.updatePasswordById(1, "654321");
}
现在我想使用原生SQL来实现根据用户名称修改密码:
@Transactional
@Modifying
@Query(value = "update users set password = :pwd where username = :name", nativeQuery = true) //使用原生SQL,和Mybatis一样,这里使用 :名称 表示参数,当然也可以继续用上面那种方式。
int updatePasswordByUsername(@Param("name") String username, //我们可以使用@Param指定名称
@Param("pwd") String newPassword);
@Test
void updateAccount(){
repository.updatePasswordByUsername("Admin", "654321");
}
通过编写原生SQL,在一定程度上弥补了SQL不可控的问题。
虽然JPA能够为我们带来非常便捷的开发体验,但是正是因为太便捷了,保姆级的体验有时也会适得其反,尤其是一些国内用到复杂查询业务的项目,可能开发到后期特别庞大时,就只能从底层SQL语句开始进行优化,而由于JPA尽可能地在屏蔽我们对SQL语句的编写,所以后期优化是个大问题,并且Hibernate相对于Mybatis来说,更加重量级。不过,在微服务的时代,单体项目一般不会太大,JPA的劣势并没有太明显地体现出来。
MybatisPlus框架
前面我们体验了JPA带来的快速开发体验,但是我们发现,面对一些复杂查询时,JPA似乎有点力不从心,反观稍微麻烦一点的Mybatis却能够手动编写SQL,使用起来更加灵活,那么有没有一种既能灵活掌控逻辑又能快速完成开发的持久层框架呢?
MyBatis-Plus(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
MybatisPlus的愿景是成为 MyBatis 最好的搭档,就像 魂斗罗 中的 1P、2P,基友搭配,效率翻倍。

官方网站地址:https://baomidou.com
MybatisPlus具有以下特性:
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
框架整体结构如下:

不过,光说还是不能体会到它带来的便捷性,我们接着就来上手体验一下。
快速上手
跟之前一样,还是添加依赖:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
配置文件依然只需要配置数据源即可:
spring:
datasource:
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
然后依然是实体类,可以直接映射到数据库中的表:
@Data
@TableName("user") //对应的表名
public class User {
@TableId(type = IdType.AUTO) //对应的主键
int id;
@TableField("name") //对应的字段
String name;
@TableField("email")
String email;
@TableField("password")
String password;
}
接着,我们就可以编写一个Mapper来操作了:
@Mapper
public interface UserMapper extends BaseMapper<User> {
//使用方式与JPA极其相似,同样是继承一个基础的模版Mapper
//这个模版里面提供了预设的大量方法直接使用,跟JPA如出一辙
}
这里我们就来写一个简单测试用例:
@SpringBootTest
class DemoApplicationTests {
@Resource
UserMapper mapper;
@Test
void contextLoads() {
System.out.println(mapper.selectById(1)); //同样可以直接selectById,非常快速方便
}
}
可以看到这个Mapper提供的方法还是很丰富的:

后续的板块我们将详细介绍它的使用方式。
条件构造器
对于一些复杂查询的情况,MybatisPlus支持我们自己构造QueryWrapper用于复杂条件查询:
@Test
void contextLoads() {
QueryWrapper<User> wrapper = new QueryWrapper<>(); //复杂查询可以使用QueryWrapper来完成
wrapper
.select("id", "name", "email", "password") //可以自定义选择哪些字段
.ge("id", 2) //选择判断id大于等于1的所有数据
.orderByDesc("id"); //根据id字段进行降序排序
System.out.println(mapper.selectList(wrapper)); //Mapper同样支持使用QueryWrapper进行查询
}
通过使用上面的QueryWrapper对象进行查询,也就等价于下面的SQL语句:
select id,name,email,password from user where id >= 2 order by id desc
我们可以在配置中开启SQL日志打印:
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
最后得到的结果如下:

有些时候我们遇到需要批处理的情况,也可以直接使用批处理操作:
@Test
void contextLoads() {
//支持批处理操作,我们可以一次性删除多个指定ID的用户
int count = mapper.deleteBatchIds(List.of(1, 3));
System.out.println(count);
}

我们也可以快速进行分页查询操作,不过在执行前我们需要先配置一下:
@Configuration
public class MybatisConfiguration {
@Bean
public MybatisPlusInterceptor paginationInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//添加分页拦截器到MybatisPlusInterceptor中
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
这样我们就可以愉快地使用分页功能了:
@Test
void contextLoads() {
//这里我们将用户表分2页,并获取第一页的数据
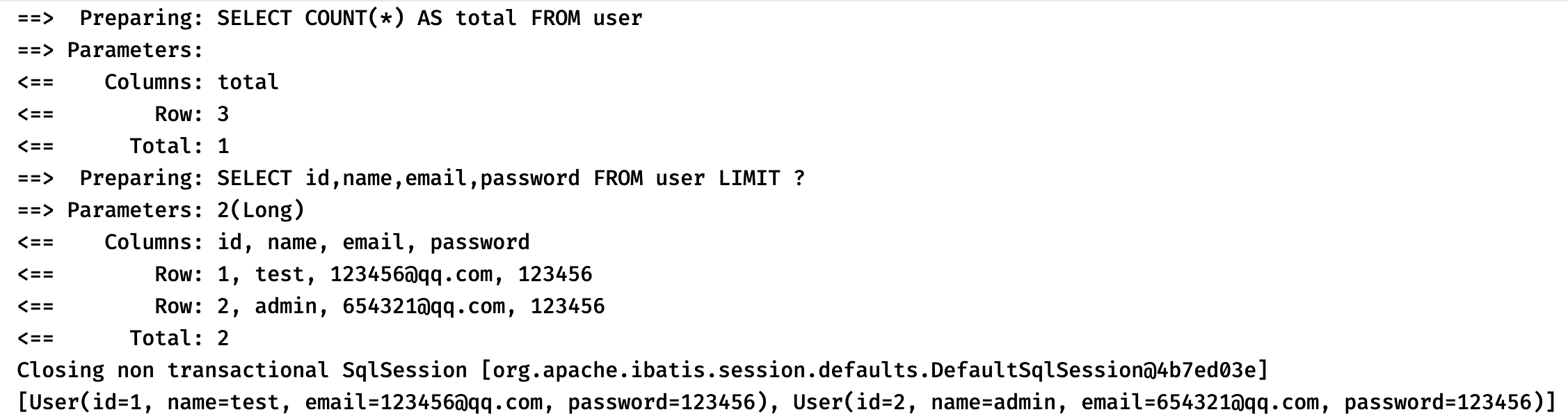
Page<User> page = mapper.selectPage(Page.of(1, 2), Wrappers.emptyWrapper());
System.out.println(page.getRecords()); //获取分页之后的数据
}
对于数据更新操作,我们也可以使用UpdateWrapper非常方便的来完成:
@Test
void contextLoads() {
UpdateWrapper<User> wrapper = new UpdateWrapper<>();
wrapper
.set("name", "lbw")
.eq("id", 1);
System.out.println(mapper.update(null, wrapper));
}
这样就可以快速完成更新操作了:

QueryWrapper和UpdateWrapper还有专门支持Java 8新增的Lambda表达式的特殊实现,可以直接以函数式的形式进行编写,使用方法是一样的,这里简单演示几个:
@Test
void contextLoads() {
LambdaQueryWrapper<User> wrapper = Wrappers
.<User>lambdaQuery()
.eq(User::getId, 2) //比如我们需要选择id为2的用户,前面传入方法引用,后面比的值
.select(User::getName, User::getId); //比如我们只需要选择name和id,那就传入对应的get方法引用
System.out.println(mapper.selectOne(wrapper));
}
不过感觉可读性似乎没有不用Lambda高啊。
接口基本操作
虽然使用MybatisPlus提供的BaseMapper已经很方便了,但是我们的业务中,实际上很多时候也是一样的工作,都是去简单调用底层的Mapper做一个很简单的事情,那么能不能干脆把Service也给弄个模版?MybatisPlus为我们提供了很方便的CRUD接口,直接实现了各种业务中会用到的增删改查操作。
我们只需要继承即可:
@Service
public interface UserService extends IService<User> {
//除了继承模版,我们也可以把它当成普通Service添加自己需要的方法
}
接着我们还需要编写一个实现类,这个实现类就是UserService的实现:
@Service //需要继承ServiceImpl才能实现那些默认的CRUD方法
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
使用起来也很方便,整合了超多方法:

比如我们想批量插入一组用户数据到数据库中:
@Test
void contextLoads() {
List<User> users = List.of(new User("xxx"), new User("yyy"));
//预设方法中已经支持批量保存了,这相比我们直接用for效率高不少
service.saveBatch(users);
}
还有更加方便快捷的保存或更新操作,当数据不存在时(通过主键ID判断)则插入新数据,否则就更新数据:
@Test
void contextLoads() {
service.saveOrUpdate(new User("aaa"));
}
我们也可以直接使用Service来进行链式查询,写法非常舒服:
@Test
void contextLoads() {
User one = service.query().eq("id", 1).one();
System.out.println(one);
}
新版代码生成器
最后我们再来隆重介绍一下MybatisPlus的代码生成器,这个东西可谓是拯救了千千万万学子的毕设啊。
它能够根据数据库做到代码的一键生成,能做到什么程度呢?

你没看错,整个项目从Mapper到Controller,所有的东西全部都给你生成好了,你只管把需要补充的业务给写了就行,这是真正的把饭给喂到你嘴边的行为,是广大学子的毕设大杀器。
那么我们就来看看,这玩意怎么去用的,首先我们需要先把整个项目的数据库给创建好,创建好之后,我们继续下一步,这里我们从头开始创建一个项目,感受一下它的强大,首先创建一个普通的SpringBoot项目:

接着我们导入一会需要用到的依赖:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>
然后再配置一下数据源:
spring:
datasource:
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
接着我们就可以开始编写自动生成脚本了,这里依然选择测试类,用到FastAutoGenerator作为生成器:
@Test
void contextLoads() {
FastAutoGenerator
//首先使用create来配置数据库链接信息
.create(new DataSourceConfig.Builder(dataSource))
.execute();
}
接着我们配置一下全局设置,这些会影响一会生成的代码:
@Test
void contextLoads() {
FastAutoGenerator
.create(new DataSourceConfig.Builder(dataSource))
.globalConfig(builder -> {
builder.author("lbw"); //作者信息,一会会变成注释
builder.commentDate("2024-01-01"); //日期信息,一会会变成注释
builder.outputDir("src/main/java"); //输出目录设置为当前项目的目录
})
.execute();
}
然后是打包设置,也就是项目的生成的包等等,这里简单配置一下:
@Test
void contextLoads() {
FastAutoGenerator
...
//打包设置,这里设置一下包名就行,注意跟我们项目包名设置为一致的
.packageConfig(builder -> builder.parent("com.example"))
.strategyConfig(builder -> {
//设置为所有Mapper添加@Mapper注解
builder
.mapperBuilder()
.mapperAnnotation(Mapper.class)
.build();
})
.execute();
}
接着我们就可以直接执行了这个脚本了:

现在,可以看到我们的项目中已经出现自动生成代码了:

我们也可以直接运行这个项目:

速度可以说是非常之快,一个项目模版就搭建完成了,我们只需要接着写业务就可以了,当然如果各位小伙伴需要更多定制化的话,可以在官网查看其他的配置:https://baomidou.com/pages/981406/
对于一些有特殊要求的用户来说,我们希望能够以自己的模版来进行生产,怎么才能修改它自动生成的代码模版呢,我们可以直接找到mybatis-plus-generator的源码:

生成模版都在在这个里面有写,我们要做的就是去修改这些模版,变成我们自己希望的样子,由于默认的模版解析引擎为Velocity,我们需要复制以.vm结尾的文件到resource随便一个目录中,然后随便改:

接着我们配置一下模版:
@Test
void contextLoads() {
FastAutoGenerator
...
.strategyConfig(builder -> {
builder
.mapperBuilder()
.enableFileOverride() //开启文件重写,自动覆盖新的
.mapperAnnotation(Mapper.class)
.build();
})
.templateConfig(builder -> {
builder.mapper("/template/mapper.java.vm");
})
.execute();
}
这样,新生成的代码中就是按照我们自己的模版来定义了:

有了代码生成器,我们工 (划) 作 (水) 效率更上一层楼啦~
该博客转载自B站UP青空的霞光
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝

{kind=link}